|
Maria-Florina Balcan, Nicholas J. A. Harvey.
43rd Annual ACM Symposium on Theory of Computing (STOC 11),
San Jose, CA, June 2011.
PDF.
arXiv,
August 2010.
PDF.
 There has recently been significant interest in the machine learning community on understanding
and using submodular functions. Despite this recent interest, little is known about submodular functions
from a learning theory perspective. Motivated by applications such as pricing goods in economics, this
paper considers PAC-style learning of submodular functions in a distributional setting.
There has recently been significant interest in the machine learning community on understanding
and using submodular functions. Despite this recent interest, little is known about submodular functions
from a learning theory perspective. Motivated by applications such as pricing goods in economics, this
paper considers PAC-style learning of submodular functions in a distributional setting.
A problem instance consists of a distribution on
{0,1}n
and a real-valued function on
{0,1}n
that is non-negative, monotone
and submodular. We are given poly(n) samples from this distribution, along
with the values of the function at those sample points. The task is to
approximate the value of the function to within a multiplicative factor at
subsequent sample points drawn from the same distribution, with sufficiently high
probability. We prove several results for this problem.
-
If the function is Lipschitz and the distribution is a
product distribution, such as the uniform distribution, then
a good approximation is possible: there is an
algorithm that approximates the function to within a factor O(log (1/ε)) on a
set of measure 1-ε, for any ε>0.
-
If we do not assume that the distribution is a product distribution, then the approximation factor
must be much worse: no algorithm can approximate the function to within a factor of
O(n1/3/log n)
on a set of measure 1/2+ε, for any constant ε>0.
This holds even if the function is Lipschitz.
-
On the other hand, this negative result is nearly tight:
for an arbitrary distribution, there is an algorithm that approximates
the function to within a factor of
n1/2
on a set of measure 1-ε.
Our work combines central issues in optimization (submodular functions and matroids) with central
topics in learning (distributional learning and PAC-style analyses) and with central concepts in pseudorandomness
(lossless expander graphs). Our analysis involves a twist on the usual learning theory models
and uncovers some interesting structural and extremal properties of submodular functions, which we
suspect are likely to be useful in other contexts. In particular, to prove our general lower bound, we use
lossless expanders to construct a new family of matroids which can take wildly varying rank values on
superpolynomially many sets; no such construction was previously known.
|
 Submodular functions are a key concept in combinatorial optimization.
Algorithms that involve submodular functions usually assume that they are given by
a (value) oracle. Many interesting problems involving
submodular functions can be solved using only polynomially many queries to the oracle,
e.g., exact minimization or approximate maximization.
Submodular functions are a key concept in combinatorial optimization.
Algorithms that involve submodular functions usually assume that they are given by
a (value) oracle. Many interesting problems involving
submodular functions can be solved using only polynomially many queries to the oracle,
e.g., exact minimization or approximate maximization.
 Given a matrix whose entries are a mixture
of numeric values and symbolic variables, the
matrix completion problem is to assign values to the
variables so as to maximize the resulting matrix rank.
This problem has deep connections to computational complexity
and numerous important algorithmic applications.
Determining the complexity of this problem is a
fundamental open question in computational complexity.
Under different settings of parameters, the problem is variously in P, in RP, or NP-hard.
We shed new light on this landscape by demonstrating a new region of NP-hard scenarios.
As a special case, we obtain the first known hardness result for matrices in which each variable
appears only twice.
Given a matrix whose entries are a mixture
of numeric values and symbolic variables, the
matrix completion problem is to assign values to the
variables so as to maximize the resulting matrix rank.
This problem has deep connections to computational complexity
and numerous important algorithmic applications.
Determining the complexity of this problem is a
fundamental open question in computational complexity.
Under different settings of parameters, the problem is variously in P, in RP, or NP-hard.
We shed new light on this landscape by demonstrating a new region of NP-hard scenarios.
As a special case, we obtain the first known hardness result for matrices in which each variable
appears only twice.
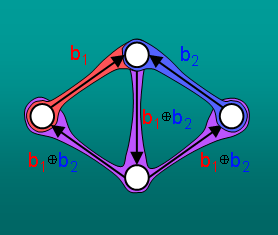 We present a new deterministic algorithm to construct network codes for multicast problems,
a particular class of network information flow problems.
Our algorithm easily generalizes to several variants of multicast problems.
Our approach is based on a new algorithm for maximum-rank completion
of mixed matrices---taking a matrix whose entries are a mixture
of numeric values and symbolic variables, and assigning values to the
variables so as to maximize the resulting matrix rank.
Our algorithm is faster than existing deterministic algorithms and can
operate over a smaller field.
We present a new deterministic algorithm to construct network codes for multicast problems,
a particular class of network information flow problems.
Our algorithm easily generalizes to several variants of multicast problems.
Our approach is based on a new algorithm for maximum-rank completion
of mixed matrices---taking a matrix whose entries are a mixture
of numeric values and symbolic variables, and assigning values to the
variables so as to maximize the resulting matrix rank.
Our algorithm is faster than existing deterministic algorithms and can
operate over a smaller field.