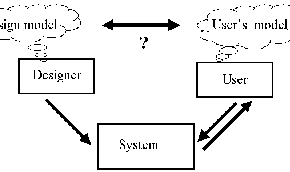
Ideally these two models should match and the system implementation should follow them closely. The system would then be more immediately useful to the analyst. Moreover, it would be more easily extended to new areas by the user; the step from user to designer would be small.
To better match models, Norman (1988) recommends the designer:
There are two types of existing knowledge common between the designer and the user of a statistical analysis system. The first is the everyday sort such as switches, push-buttons, dials, and gauges which can be mimicked to good effect in a visual display. The familiarity of the visual representation makes its use obvious to the user.
The second is the knowledge about statistical analysis which, although specialized, is shared by both user and designer. In the early command line systems this was evident primarily in the names of commands. In early direct manipulation interfaces, it is first evident through common interactive statistical graphics.
Strictly speaking, it is not necessary to make maximal use of the existing common knowledge. If the designer is successful in communicating, using, and reinforcing the model then the user can be trained to adopt it. In the extreme, a user who learned about statistical analysis solely by interacting with a single statistical system might very well have a mental model essentially coincident with that of the designer. When computational resources are scarce this is particularly desirable.
Ever faster processors and cheaper memory means that we can now afford to devote more resources to system software which better models existing statistical knowledge. Matching fundamental system components directly to the basic structures of statistical analysis maximizes use of the specialized knowledge common between designer and user.
This approach has important consequences. First, communicating the system model to a statistically trained user should be straightforward. Second, the designer writing code in terms of these fundamental components is actively exercising the model and providing the user with easily understood means to tailor the system to his/her needs. Third, such use reinforces the model.
Not surprisingly, there is abundant structure in statistical knowledge relevant to interactive analysis. Many statistical concepts are quite naturally represented as data structures, for example:
Generic functions and specialized methods are also useful in modelling statistical concepts which might not be represented in a hierarchy. In Quail for example, the generic function random-value applies equally to any instance of a distribution and to any dataset. This is so that the user may regard the dataset as an empirical distribution, as in resampling procedures, without changing its class to some kind of distribution.
In Quail this is accomplished by having every graphic component maintain a pointer to the relevant statistical object being displayed - this is its viewed object (e.g. see Hurley and Oldford, 1991). A fitted line, for example, would have a pointer to the fit-object which it visually represents in a plot. Conversely, every statistical object in Quail returns a graphics object when asked for its display (see Oldford, 1998, 1997 for more discussion).