The proof of the completeness of PC given in
Theorem II.9.9 of LMCS actually provides us with a straightforward
algorithm to find derivations of tautologies. If we are given a tautology ![]() then we diagram the algorithm as follows:
then we diagram the algorithm as follows:
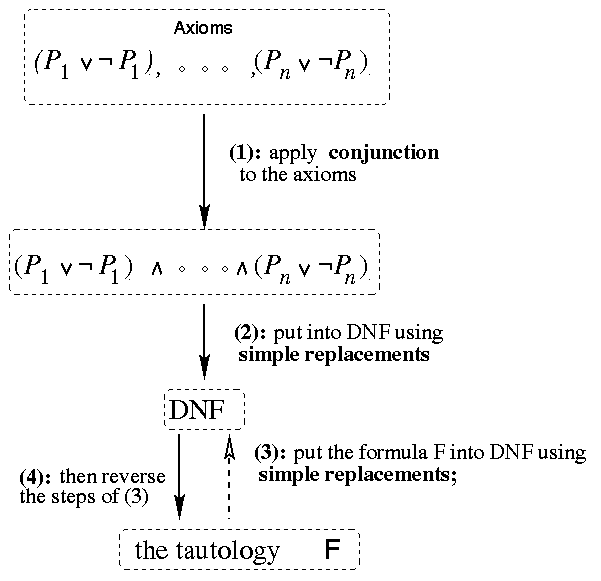
Thus we see the four key parts of the algorithm:
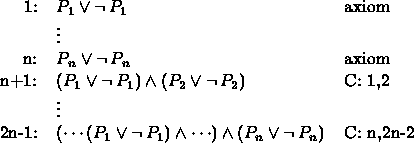
For the second part one needs at least ![]() steps (just to apply the distributive
laws). We illustrate for the case n=2. At this point our current notation
becomes difficult to read, so for the rest of this subsection we switch to an abbreviated
notation, namely we will use
FG for
steps (just to apply the distributive
laws). We illustrate for the case n=2. At this point our current notation
becomes difficult to read, so for the rest of this subsection we switch to an abbreviated
notation, namely we will use
FG for ![]() , and
, and ![]() for
for ![]() . Also we will (for the
time being) say
. Also we will (for the
time being) say ![]() has higher precedence than
has higher precedence than ![]() , so
, so ![]() means
means ![]() . This will allow us to dispense with many parentheses.
. This will allow us to dispense with many parentheses.
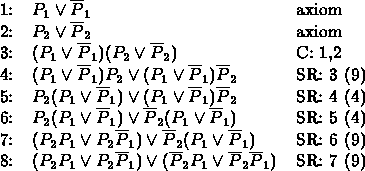
So we needed the first 3 steps to obtain ![]() ,
the first part of the procedure, and then
5 steps to put this into disjunctive normal form. Of course one may want to rewrite
this so that one has the DNF-constituents ordered according to the usual ordering of the rows of
a truth table, and left associated, namely as
,
the first part of the procedure, and then
5 steps to put this into disjunctive normal form. Of course one may want to rewrite
this so that one has the DNF-constituents ordered according to the usual ordering of the rows of
a truth table, and left associated, namely as
![]()
After all, to have a DNF one needs to specify the order in which the DNF constituents are written, and how they are parenthesized. To go from line (8) above to this form will require 8 additional steps, applying commutativity and associativity (as simple replacement rules):
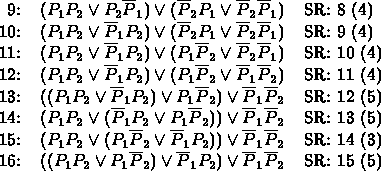
For larger n the second part of the algorithm explodes in the amount of work one needs to
do because of the exponential lower bound ![]() on the number of steps given above.
For n=5 variables this is already 56 steps, i.e., at least a page of work. And we still
have the third part to worry about. This can be the wild card. If F is almost in DNF then
there will not be much work to do. But it can be the most tedious part of the algorithm.
on the number of steps given above.
For n=5 variables this is already 56 steps, i.e., at least a page of work. And we still
have the third part to worry about. This can be the wild card. If F is almost in DNF then
there will not be much work to do. But it can be the most tedious part of the algorithm.
Let us return to the two examples that we presented after defining the notion of derivation (on page 76) and apply the above algorithm to them, and compare the results with our earlier derivations.
Example 1 (See Example II.9.5.)
The following uses the above algorithm to derive ![]() .
.
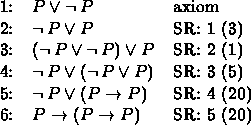
This compares quite favorably to the derivation in Example II.9.5, requiring only 1 more step. Part 1 and part 2 of the algorithm collapse into the first step above. Reading steps 1 through 6, in reverse order, we see the procedure for putting step 6 into its disjunctive normal form.
The following uses the algorithm to derive ![]() .
.
Example 2 (See Example II.9.6.)

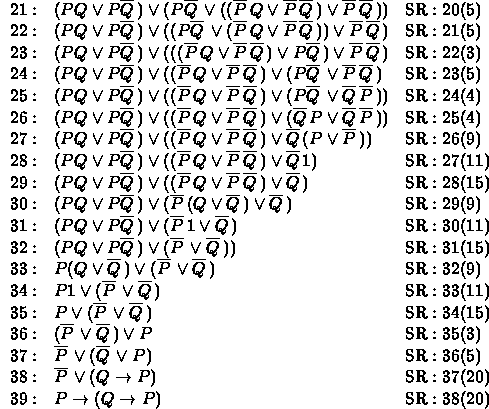
This is rather painful when compared to the 7 line derivation in Example II.9.6. Looking over the steps we see that part 1 is steps 1-3, part 2 is steps 3-13, part 3 is steps 42-13, and part 4 is steps 13-42. In this case we see that part 3 is the most demanding of our resources.
So the moral of this section is: yes, we do have a straightforward algorithm to find derivations. But it is probably a much better idea to look for a short derivation taking advantage of the many rules available in PC. That is why we have so many more rules than are needed to prove completeness.