# jemdoc: menu{MENU}{research.html},title{Research}, showsource, analytics{UA-64995133-3}
= Research Interests
{{}}
I am interested in the design and analysis of Monte Carlo experiments for complex financial, actuarial, and operations research applications.
I am also interested in stochastic optimization, machine learning and data science, and enterprise risk management.
I especially enjoy research in the intersections of these fields such as simulation optimization, simulation analytics, portfolio optimization, etc. As a researcher and an actuary, my research is sometimes guided towards applying advanced theoretical methodologies to solve complex practical problems.
Our research group currently undertakes multiple related but different research topics:
- Application of machine learning and simulation analytics for pricing and risk management of large portfolios of financial and actuarial instruments.
- Efficient simulation procedure for tail risk estimation for complex variable annuity (VA) products.
- Development and analysis of green simulation, particularly green simulation via the likelihood ratio method.
- Application of green simulation via likelihood ratio in uncertainty quantification and simulation optimization.
{{}}
#####
{{}}
== Simulation Analytics for Risk Management of Large Variable Annuity Portfolios
~~~
Simulation analytics is a new simulation output analysis paradigm that views simulations as a controlled way of generating and collecting data, after which predictive analytics methods can be applied.
Simulation analytics takes advantages of the flexibility in simulation modeling of complex systems, its ability to generate large amount of data, and the trending development of novel data science tools.
This line of research aims to develop novel simulation analytics methods:
(1) Utilizes some problem structures such as tail risk estimation to circumvent (hopefully many) inner simulations by efficiently identify tail scenarios, where a given simulation budget will then be concentrated.
(2) Utilizes novel supervised and unsupervised learning methods such as Gaussian process modeling and clustering improve the overall efficiency of computationally demanding simulation experiments.
Nested simulation is a popular tool for risk management of large portfolios of financial and insurance products.
It is, however, notoriously known for its heavy computational burden; sometimes prohibitively so.
In some cases, such as tail risk estimation, only the simulation outputs in the tail scenarios affect the accuracy of the risk estimator; majority of the simulation outputs are under-utilized for finding the ranks of estimates in different scenarios.
Using known data analytics methods, such as proxy modeling, we are able to identify tail scenarios with minimal computation, then concentrate a given simulation budget to the importance tail scenarios.
We provide theoretical support and intuition for such importance allocated nested simulation (IANS) procedure.
Given a large portfolio of financial and actuarial products, valuing every product using simulation is extremely time-consuming.
Viewing simulation as a data generator, however, can take advantages of existing data analytics methods.
For instance, unsupervised learning such a clustering can be used to identify a few key representative products in the portfolio.
After valuing these representative products via simulation, supervised learning methods such as Gaussian process modeling can be calibrated to learn the simulation model's input-output relationship.
Such calibrated model can be used to efficiently valuate every product in the portfolio.
Such compressor-simulator-predictor procedure is shown to be highly efficient and effective.
~~~
=== Selected Publications
- /*Efficient Nested Simulation for Conditional Tail Expectation of Variable Annuities (2020).*/ North American Actuarial Journal (NAAJ) \n
[https://uwaterloo.ca/statistics-and-actuarial-science/about/people/odang Ou Dang], [http://www.math.uwaterloo.ca/~mbfeng/ Mingbin Feng], and [https://uwaterloo.ca/statistics-and-actuarial-science/people-profiles/mary-hardy Mary Hardy].\n
[papers/2020_IANSNAAJ.bib Bibtex]~~~[https://doi.org/10.1080/10920277.2019.1636399 DOI]~~~[papers/2020_IANSNAAJ.pdf PDF {{ }}]\n
- /*Efficient Simulation Designs for Valuation of Large Variable Annuity Portfolios (2020).*/ North American Actuarial Journal (NAAJ) \n
[http://www.math.uwaterloo.ca/~mbfeng/ Mingbin Feng], Zhenni Tan, and Jiayi Zheng\n
[papers/2020_VAPort.bib Bibtex]~~~[https://doi.org/10.1080/10920277.2019.1685394 DOI]~~~[papers/2020_VAPort.pdf PDF {{}}]\n
{{}}
##### Green simulation card
{{}}
== Green Simulation: recycle and reuse simulation outputs
~~~
{{
}}]\n
- /*Efficient Simulation Designs for Valuation of Large Variable Annuity Portfolios (2020).*/ North American Actuarial Journal (NAAJ) \n
[http://www.math.uwaterloo.ca/~mbfeng/ Mingbin Feng], Zhenni Tan, and Jiayi Zheng\n
[papers/2020_VAPort.bib Bibtex]~~~[https://doi.org/10.1080/10920277.2019.1685394 DOI]~~~[papers/2020_VAPort.pdf PDF {{}}]\n
{{}}
##### Green simulation card
{{}}
== Green Simulation: recycle and reuse simulation outputs
~~~
{{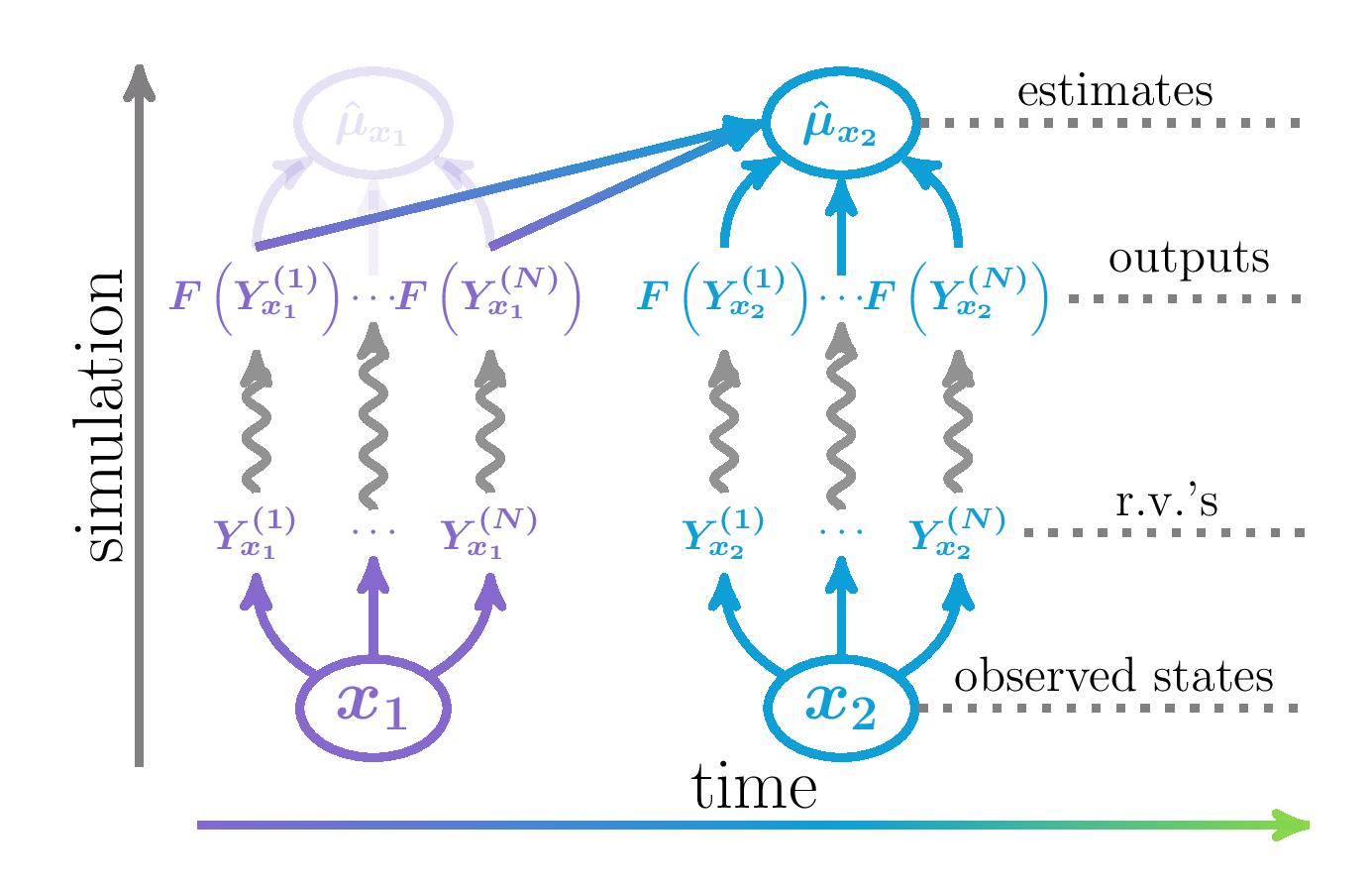 }}
Green simulation is a novel simulation design paradigm that aims to reuse and recycle simulation outputs to enhance the accuracy and computational efficiency of simulation experiments.
We propose to view simulation experiments as computational investments that not only benefit the current but also the future decision-making processes.
Our research aims to develop efficient methods of output recycling and to examine their theoretical properties and practical performances.
In many financial and actuarial applications, simulation models are often run repeatedly to perform the same task, e.g., derivative pricing with slightly different inputs, e.g., newly observed market information.
In these cases, the simulation outputs from previous experiments are informative of the current experiment.
Reusing previous simulation outputs, rather than the common practice of disgarding them, can greatly increase the simulation efficiency for the current and all future tasks.
Metamodeling is a useful tool for understanding the input-output relationship in complex black-box simulation models.
The exploration vs. exploitation tradeoff is a central problem in the simulation design for different metamodeling techniques.
Some green simulation methods, such as green simulation via likelihood ratio, can be viewed as unbiased metamodels.
By cataloging these methods, we discover metamodels that are both unbiased and have low variance and also identify new metamodels that have not been studied before.
#Nested simulation is a common tool for solving operations research and risk management problems.
For instance, bootstrap-based input uncertainty quantification and risk estimation for dynamic hedging programs.
In a typical nested simulation procedure, estimation for each outer scenario uses only the inner simulations associated with that scenario.
We propose pooling inner simulations from all outer scenarios to estimate for every scenario.
Such pooling of inner simulation greatly improves accuracy, reducing computations, or both.
~~~
=== Selected Publications
- /*Green Simulation with Database Monte Carlo (2020).*/ \n
[http://www.math.uwaterloo.ca/~mbfeng/ Mingbin Feng] and [http://users.iems.northwestern.edu/~staum/ Jeremy Staum]. ACM Transactions on Modeling and Computer Simulation (TOMACS)\n
Forthcoming. Accepted for publication in Nov 2020.\n
- /*Green Simulation: Reusing the Output of Repeated Experiments (2017)*/\n
[http://www.math.uwaterloo.ca/~mbfeng/ Mingbin Feng] and [http://users.iems.northwestern.edu/~staum/ Jeremy Staum]. ACM Transactions on Modeling and Computer Simulation (TOMACS)\n
[papers/2017_GreenSim.bib Bibtex]~~~[https://doi.org/10.1145/3129130 DOI]~~~[papers/2017_GreenSim.pdf PDF {{}}]\n
{{}}
#################################################
{{}}
== Systemic Risk Components in a Network Model of Contagion
~~~
{{
}}
Green simulation is a novel simulation design paradigm that aims to reuse and recycle simulation outputs to enhance the accuracy and computational efficiency of simulation experiments.
We propose to view simulation experiments as computational investments that not only benefit the current but also the future decision-making processes.
Our research aims to develop efficient methods of output recycling and to examine their theoretical properties and practical performances.
In many financial and actuarial applications, simulation models are often run repeatedly to perform the same task, e.g., derivative pricing with slightly different inputs, e.g., newly observed market information.
In these cases, the simulation outputs from previous experiments are informative of the current experiment.
Reusing previous simulation outputs, rather than the common practice of disgarding them, can greatly increase the simulation efficiency for the current and all future tasks.
Metamodeling is a useful tool for understanding the input-output relationship in complex black-box simulation models.
The exploration vs. exploitation tradeoff is a central problem in the simulation design for different metamodeling techniques.
Some green simulation methods, such as green simulation via likelihood ratio, can be viewed as unbiased metamodels.
By cataloging these methods, we discover metamodels that are both unbiased and have low variance and also identify new metamodels that have not been studied before.
#Nested simulation is a common tool for solving operations research and risk management problems.
For instance, bootstrap-based input uncertainty quantification and risk estimation for dynamic hedging programs.
In a typical nested simulation procedure, estimation for each outer scenario uses only the inner simulations associated with that scenario.
We propose pooling inner simulations from all outer scenarios to estimate for every scenario.
Such pooling of inner simulation greatly improves accuracy, reducing computations, or both.
~~~
=== Selected Publications
- /*Green Simulation with Database Monte Carlo (2020).*/ \n
[http://www.math.uwaterloo.ca/~mbfeng/ Mingbin Feng] and [http://users.iems.northwestern.edu/~staum/ Jeremy Staum]. ACM Transactions on Modeling and Computer Simulation (TOMACS)\n
Forthcoming. Accepted for publication in Nov 2020.\n
- /*Green Simulation: Reusing the Output of Repeated Experiments (2017)*/\n
[http://www.math.uwaterloo.ca/~mbfeng/ Mingbin Feng] and [http://users.iems.northwestern.edu/~staum/ Jeremy Staum]. ACM Transactions on Modeling and Computer Simulation (TOMACS)\n
[papers/2017_GreenSim.bib Bibtex]~~~[https://doi.org/10.1145/3129130 DOI]~~~[papers/2017_GreenSim.pdf PDF {{}}]\n
{{}}
#################################################
{{}}
== Systemic Risk Components in a Network Model of Contagion
~~~
{{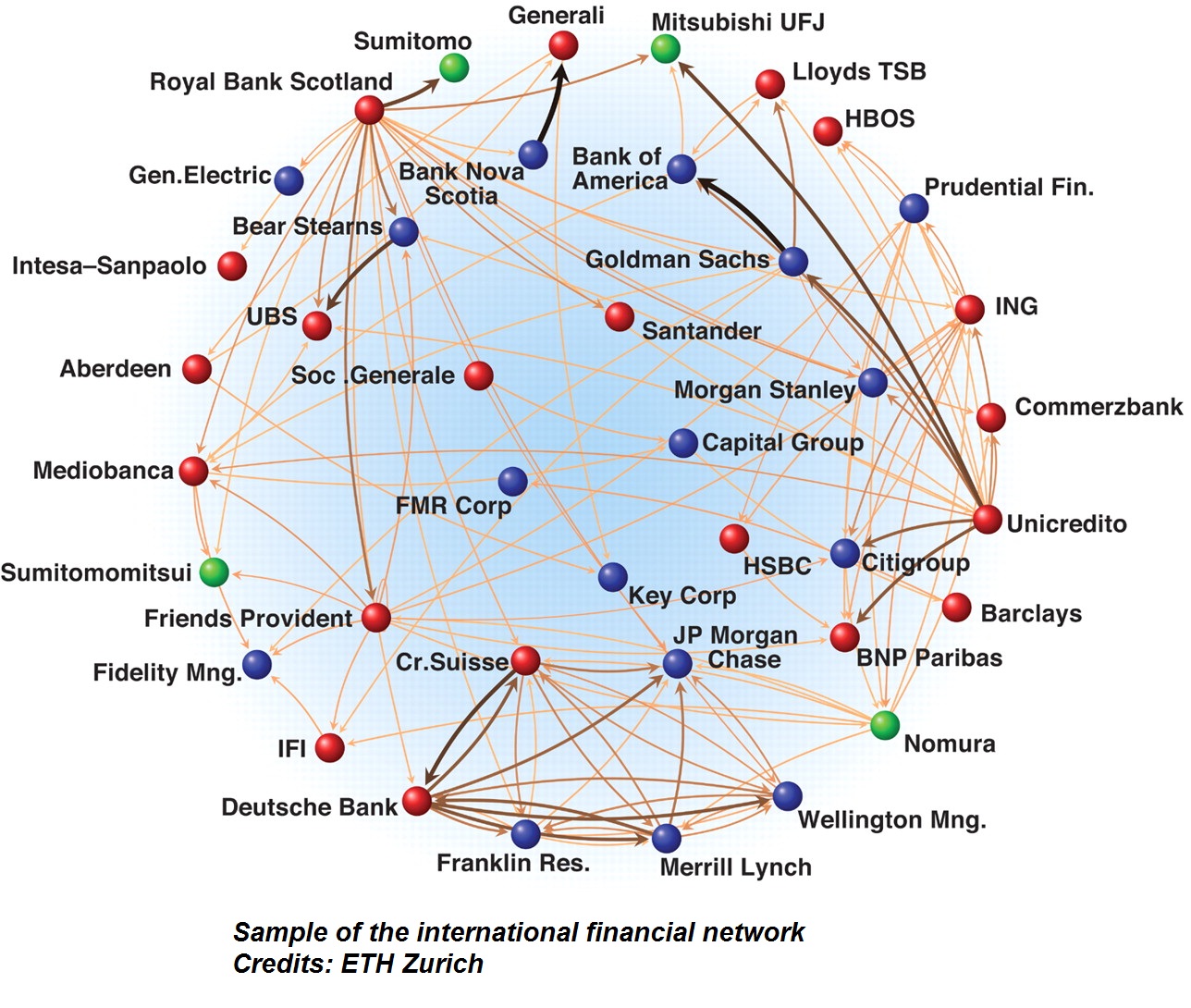 }}
Financial entities around the globe are interconnected and this giant global financial network requires sophisticated systemic risk management.
This research addresses the question of risk attribution, "Who contributed how much risk to the network's overall systemic risk?", which is a key question in systemic risk management.
Seven risk attribution methods are developed to suit different systemic risk management objectives in different time and scale.
~~~
=== Papers
- */Systemic Risk Components in a Network Model of Contagion (2015)./* IIE Transactions.\n
[http://users.iems.northwestern.edu/~staum/ Jeremy Staum], [http://www.math.uwaterloo.ca/~mbfeng/ Mingbin Feng], and Ming Liu\n
[papers/2015_SRCNMC.bib Bibtex]~~~[https://doi.org/10.1080/0740817X.2015.1110650 DOI]~~~[papers/2015_SRCNMC.pdf PDF {{}}]\n
{{}}
###################################################
{{}}
== Portfolio Optimization Problems with VaR and CVaR Constraints
~~~
{}{raw}
Value-at-Risk (VaR) and Conditional Value-at-Risk (CVaR) are common risk measures in finance and insurance. General classes of risk measures such as coherent risk measures and distortion risk measures have been extensively studied. Portfolio optimization problems using these measures are important in research and in practice.
VaR portfolio optimization problems are non-convex in general can needs to be solved by integer programming. Nonetheless, tight big-M constraints can be derived to solve the resulting integer program efficiently. Also, the linear programming framework can be extended to a general class of risk measures called the coherent distortion risk measures.
~~~
=== Papers
- */Practical Algorithms for Value-at-Risk Portfolio Optimization Problems (2015)./* Quantitative Finance Letters.\n
[http://www.math.uwaterloo.ca/~mbfeng/ Mingbin Feng], [http://users.iems.northwestern.edu/~andreasw/index.html Andreas Waechter], and [http://users.iems.northwestern.edu/~staum/ Jeremy Staum]\n
[papers/2015_VaROpt.bib Bibtex]~~~[https://doi.org/10.1080/21649502.2014.995214 DOI]~~~[papers/2015_VaROpt.pdf PDF {{}}]\n
- */oherent Distortion Risk Measures in Portfolio Selection (2012)./* Systems Engineering Procedia.\n
[http://www.math.uwaterloo.ca/~mbfeng/ Mingbin Feng] and [https://uwaterloo.ca/statistics-and-actuarial-science/people-profiles/ken-seng-tan Ken Seng Tan]\n
[papers/2012_CDRM.bib Bibtex]~~~[https://doi.org/10.1016/j.sepro.2011.11.045 DOI]~~~[papers/2012_CDRM.pdf PDF {{}}]\n
{{}}
###################################################
{{}}
== Complementarity Formulations of L0-norm Optimization Problems
~~~
{}{raw}
In many application it may be desirable to obtain sparse solutions. Minimizing the number of nonzeroes, L0-norm, of the solution is a difficult nonconvex optimization problem and is often approximated by the convex problem of minimizing the L1-norm. We consider exact formulations as mathematical programs with complementarity constraints and their reformulations as smooth nonlinear programs. We discuss properties of the various formulations and their connections to the original L0-minimization problem in terms of stationarity conditions, as well as local and global optimality. Numerical experiments using randomly generated problems show that standard nonlinear programming solvers, applied to the smooth but nonconvex equivalent reformulations, are often able to find sparser solutions than those obtained by the convex L1-approximation.
~~~
=== Papers
- */Complementarity Formulations of L0-norm Optimization Problems (2018)./* Pacific Journal of Optimization, Volume 14, Number 2, 273-305, 2018. \n
[http://www.math.uwaterloo.ca/~mbfeng/ Mingbin Feng], [http://homepages.rpi.edu/~mitchj/ John Mitchell], [http://ise.usc.edu/directory/jong-shi-pang.htm Jong-Shi Pang], Xi Shen, [http://users.iems.northwestern.edu/~andreasw/index.html Andreas Waechter] \n
[papers/2018_L0Opt.bib Bibtex]~~~[papers/2018_L0Opt.pdf PDF {{}}]\n
{{}}
}}
Financial entities around the globe are interconnected and this giant global financial network requires sophisticated systemic risk management.
This research addresses the question of risk attribution, "Who contributed how much risk to the network's overall systemic risk?", which is a key question in systemic risk management.
Seven risk attribution methods are developed to suit different systemic risk management objectives in different time and scale.
~~~
=== Papers
- */Systemic Risk Components in a Network Model of Contagion (2015)./* IIE Transactions.\n
[http://users.iems.northwestern.edu/~staum/ Jeremy Staum], [http://www.math.uwaterloo.ca/~mbfeng/ Mingbin Feng], and Ming Liu\n
[papers/2015_SRCNMC.bib Bibtex]~~~[https://doi.org/10.1080/0740817X.2015.1110650 DOI]~~~[papers/2015_SRCNMC.pdf PDF {{}}]\n
{{}}
###################################################
{{}}
== Portfolio Optimization Problems with VaR and CVaR Constraints
~~~
{}{raw}
Value-at-Risk (VaR) and Conditional Value-at-Risk (CVaR) are common risk measures in finance and insurance. General classes of risk measures such as coherent risk measures and distortion risk measures have been extensively studied. Portfolio optimization problems using these measures are important in research and in practice.
VaR portfolio optimization problems are non-convex in general can needs to be solved by integer programming. Nonetheless, tight big-M constraints can be derived to solve the resulting integer program efficiently. Also, the linear programming framework can be extended to a general class of risk measures called the coherent distortion risk measures.
~~~
=== Papers
- */Practical Algorithms for Value-at-Risk Portfolio Optimization Problems (2015)./* Quantitative Finance Letters.\n
[http://www.math.uwaterloo.ca/~mbfeng/ Mingbin Feng], [http://users.iems.northwestern.edu/~andreasw/index.html Andreas Waechter], and [http://users.iems.northwestern.edu/~staum/ Jeremy Staum]\n
[papers/2015_VaROpt.bib Bibtex]~~~[https://doi.org/10.1080/21649502.2014.995214 DOI]~~~[papers/2015_VaROpt.pdf PDF {{}}]\n
- */oherent Distortion Risk Measures in Portfolio Selection (2012)./* Systems Engineering Procedia.\n
[http://www.math.uwaterloo.ca/~mbfeng/ Mingbin Feng] and [https://uwaterloo.ca/statistics-and-actuarial-science/people-profiles/ken-seng-tan Ken Seng Tan]\n
[papers/2012_CDRM.bib Bibtex]~~~[https://doi.org/10.1016/j.sepro.2011.11.045 DOI]~~~[papers/2012_CDRM.pdf PDF {{}}]\n
{{}}
###################################################
{{}}
== Complementarity Formulations of L0-norm Optimization Problems
~~~
{}{raw}
In many application it may be desirable to obtain sparse solutions. Minimizing the number of nonzeroes, L0-norm, of the solution is a difficult nonconvex optimization problem and is often approximated by the convex problem of minimizing the L1-norm. We consider exact formulations as mathematical programs with complementarity constraints and their reformulations as smooth nonlinear programs. We discuss properties of the various formulations and their connections to the original L0-minimization problem in terms of stationarity conditions, as well as local and global optimality. Numerical experiments using randomly generated problems show that standard nonlinear programming solvers, applied to the smooth but nonconvex equivalent reformulations, are often able to find sparser solutions than those obtained by the convex L1-approximation.
~~~
=== Papers
- */Complementarity Formulations of L0-norm Optimization Problems (2018)./* Pacific Journal of Optimization, Volume 14, Number 2, 273-305, 2018. \n
[http://www.math.uwaterloo.ca/~mbfeng/ Mingbin Feng], [http://homepages.rpi.edu/~mitchj/ John Mitchell], [http://ise.usc.edu/directory/jong-shi-pang.htm Jong-Shi Pang], Xi Shen, [http://users.iems.northwestern.edu/~andreasw/index.html Andreas Waechter] \n
[papers/2018_L0Opt.bib Bibtex]~~~[papers/2018_L0Opt.pdf PDF {{}}]\n
{{}}