How should we measure progress in solving instances of the TSP? A simple judgment is to say that method A is superior to method B if A requires less time or less resources to solve every instance of the problem. This is a clean rule, but it makes direct rankings of methods next to impossible since closely related methods would yield such a simple comparison. It seems necessary that we considerably relax our comparison criterion.
To this end, a judge with a more open mind might be willing to ignore results on very small instances since these can be solved by all good solution techniques. Taking this further, for a given number of cities n, the judge might want to concentrate on those n-city instances that cause the most difficulty for a proposed method that he or she must evaluate. Adopting this approach, we would rank method A ahead of method B if for every large value of n the worst n-city example for A takes less time to solve than does the worst n-city example for B.
To make this comparison idea work in practice, we can analyze a given solution method to obtain a a guarantee that it takes at most some amount of time f(n) for any n-city TSP, where f(n) is shorthand for some formula that depends only on n. Now to compare two solution methods, we compare the best guarantees that we have found for them. This may of course produce misleading results since a really good method might just be tough to analyze and therefore appear to be poor when compared to a method that leads to a good analysis. On many computational problems, however, the study of algorithms+guarantees has led to some beautiful mathematical results as well as important improvements in practical problems -- this area is a primary subject of study in the field of computer science.
So what can we say about solution methods for the TSP? It is of course easy to develop methods that have a guarantee that is proportional to (n-1)! = n-1 x n-2 x n-3 x. . . x 3 x 2 x 1 since the number of n-city tours is only (n-1)!/2. A much better result was obtained in 1962 by Michael Held and Richard Karp, who found an algorithm and a guarantee that is proportional to n2 2n, that is, n x n x 2 x 2 x 2 x ... x 2, where there are n twos in the product. For any large value of n the Held-Karp guarantee is much less than (n-1)!.
For anyone interested in solving large TSP instances, it is bitter news that in the forty years since Held and Karp no better guarantee has been found for the problem. (See the nice survey paper by Gerhard Woeginger.) This is disappointing since for n=30 the Held-Karp guarantee is already quite a large number, and for n=100 it is an impossibly large number to handle with today's computing platforms.
This lack of improvement in TSP guarantees may be something we cannot avoid; with current models of computing it may well be that there simply is no solution method for the TSP that comes with an attractive performance guarantee, say one of the form nc for some fixed number c, that is, n x n x n ... x n, where n appears c times in the product. A technical discussion of this issue can be found in Stephen Cook's paper and the Clay Mathematics Institute offers a $1,000,000 prize for anyone who can settle it.
The complexity of the TSP is part of a deep question in mathematics, but the situation is that at present we get little practical information by looking at the worst-case performance of TSP solution methods.
With few good choices available, TSP researchers have resorted to measuring progress by how computer implementations of solution methods perform on collections of openly available test instances. The idea is that by growing the size and variety of test instances that can be solved we will make progress on the practical solution of the TSP. Although a weak substitute for the clean comparisons we suggested at the outset, this practical computational testing has led researchers to greatly improved TSP methods and, more importantly, the efforts have driven research in the development of general-purpose optimization tools.
The most widely used collection of TSP instances in recent computational studies is Gerd Reinelt's TSPLIB test set. The TSPLIB is made up of over 100 instances arising from industrial, geographic, and academic sources. To supplement this collection, further instances are available in the National TSP and VLSI TSP collections.
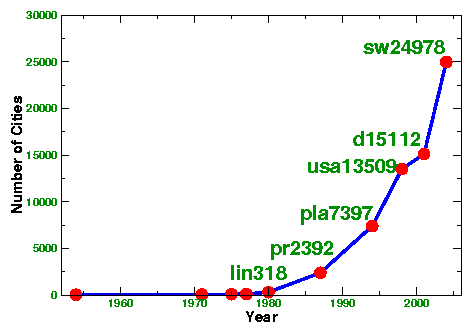
An easily recognized sign of progress on test instances is the increasing size of the largest TSPs that have been solved over the years, as we show in the plot at the top of this page. This record of progress began with Dantzig, Fulkerson, and Johnson's classic paper in 1954 where they solve a 49-city problem consisting of one city from each of the 48 states in the U.S.A. (Alaska and Hawaii were not yet states) as well as Washington, D.C. A full list of the solution milestones can be found in the TSP History pages.
A second plot of the TSP milestones, using a log-scale for the number of cities, is given below.
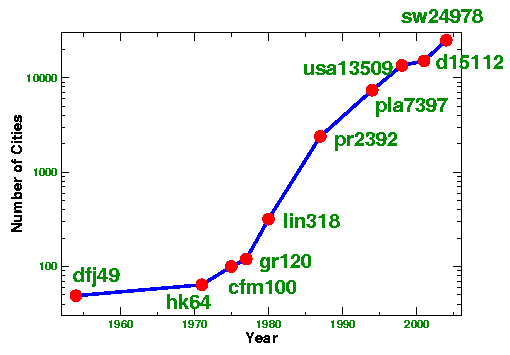
From this plot one can see the steady progress that has been made over the past 30 years. If this trend continues, we might expect to solve instances with several million cities in the next 30 years! Of course, this is only speculation and there will certainly need to be many computational improvements before we can hope to tackle such large scale instances. To see where we stand today in an attack on a 1.9 million city TSP, please view the World TSP page.
Related Links